【长文】带你搞明白内存数据库Redis
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
一、概述Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。 与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
提及我的诞生,我与关系数据库MySQL之间有着不解之缘。在我尚未降临这个世界之前,MySQL历经艰辛,伴随着互联网的飞速发展,它所承载的数据量日益庞大,用户请求也如潮水般汹涌而至。每一次的用户请求,都化作了对它无尽的读写挑战,使得MySQL备受煎熬。特别是在“双11”、“618”这样的全民购物狂欢节,对MySQL而言,无疑是难熬的考验时刻。 后来,MySQL向我透露了一个秘密。它告诉我,其实大多数的用户请求都是读取操作,而且往往都是对同一数据的反复查询,这导致它不得不花费大量时间进行磁盘I/O操作,这无疑是一种巨大的资源浪费。 有人开始深思,是否可以借鉴CPU的工作原理,为数据库也添加一个缓存机制呢?于是,我便应运而生,踏上了这个世界的舞台。 自诞生之初,我便与MySQL结下了深厚的友谊。我们携手并肩,共同出现在后端服务器的舞台上。每当应用程序需要从MySQL查询数据时,它们会首先在我这里进行登记。当再次需要这些数据时,它们会首先向我发出请求。如果我这里有它们所需的数据,它们便无需再劳烦MySQL;若我这里没有,它们才会转向MySQL寻求帮助。 如此,我便成为了MySQL的得力助手,与它共同应对着日益增长的数据挑战。我们携手前行,共同书写着数据库世界的辉煌篇章。
二、支持的数据结构大多数小伙伴都知道,为了方便使用,我支持以下这五种基本类型:
string 字符串最基础的数据结构。字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字 (整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。 字符串主要有以下几个典型使用场景:
hash 哈希类型是指键值本身又是一个键值对结构。 哈希主要有以下典型应用场景:
list 列表(list)类型是用来存储多个有序的字符串。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色
列表主要有以下几种使用场景:
set 集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一 样的是,集合中不允许有重复元素,并且集合中的元素是无序的。 集合主要有如下使用场景:
sorted set 有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个权重(score)作为排序的依据。 有序集合主要应用场景:
我还有三种特殊的数据结构类型
因为我把登记的数据都记录在内存中,不用去执行慢如蜗牛的I/O操作,所以找我要比找MySQL要省去了不少的时间呢。 可别小瞧这简单的一个改变,我可为MySQL减轻了不小的负担!随着程序的运行,我缓存的数据越来越多,有相当部分时间我都给它挡住了用户请求,这一下它可乐得清闲自在了! 有了我的加入,网络服务的性能提升了不少,这都归功于我为数据库挡下了不少的事儿。
三、缓存过期 && 缓存淘汰不过很快我发现事情不妙了,我缓存的数据都是在内存中,可是就算是在服务器上,内存的空间资源还是很有限的,不能无节制的这么存下去,我得想个办法,不然吃枣药丸。 不久,我想到了一个办法:给缓存内容设置一个超时时间,具体设置多长交给应用程序们去设置,我要做的就是把过期了的内容从我里面删除掉,及时腾出空间就行了。
超时时间有了,我该在什么时候去干这个清理的活呢? 最简单的就是定期删除,我决定100ms就做一次,一秒钟就是10次! 我清理的时候也不能一口气把所有过期的都给删除掉,我这里面存了大量的数据,要全面扫一遍的话那不知道要花多久时间,会严重影响我接待新的客户请求的!
时间紧任务重,我只好随机选择一部分来清理,能缓解内存压力就行了。 就这样过了一段日子,我发现有些个键值运气比较好,每次都没有被我的随机算法选中,每次都能幸免于难,这可不行,这些长时间过期的数据一直霸占着不少的内存空间!气抖冷! 我眼里可揉不得沙子!于是在原来定期删除的基础上,又加了一招: 那些原来逃脱我随机选择算法的键值,一旦遇到查询请求,被我发现已经超期了,那我就绝不客气,立即删除。 这种方式因为是被动式触发的,不查询就不会发生,所以也叫惰性删除! 可是,还是有部分键值,既逃脱了我的随机选择算法,又一直没有被查询,导致它们一直逍遥法外!而于此同时,可以使用的内存空间却越来越少。
而且就算退一步讲,我能够把过期的数据都删除掉,那万一过期时间设置的很长,还没等到我去清理,内存就吃满了,一样要吃枣药丸,所以我还得想个办法。 我苦思良久,终于憋出了个大招:内存淘汰策略,这一次我要彻底解决问题! 我提供了8种淘汰策略供应用程序选择,用于我遇到内存不足时该如何决策:
有了上面几套组合拳,我再也不用担心过期数据多了把空间撑满的问题了~ 我为了避免频繁的触发淘汰策略,每次会淘汰掉一批数据,淘汰的数据的大小其实是和置换的大小来确定的,如果置换的数据量大,淘汰的肯定也多。 四、缓存穿透 && 布隆过滤器我的日子过的还挺舒坦,不过MySQL大哥就没我这么舒坦了,有时候遇到些烦人的请求,查询的数据不存在,MySQL就要白忙活一场!不仅如此,因为不存在,我也没法缓存啊,导致同样的请求来了每次都要去让MySQL白忙活一场。我作为缓存的价值就没得到体现啦!这就是人们常说的缓存穿透。
这一来二去,MySQL大哥忍不住了:“唉,兄弟,能不能帮忙想个办法,把那些明知道不会有结果的查询请求给我挡一下” 这时我想到了我的另外一个好朋友:布隆过滤器
我这位朋友别的本事没有,就擅长从超大的数据集中快速告诉你查找的数据存不存在(悄悄告诉你,我的这位朋友有一点不靠谱,它告诉你存在的话不能全信,其实有可能是不存在的,不过它他要是告诉你不存在的话,那就一定不存在,同时他也不支持删除元素)。它是一个连续的数据结构,每个存储位存储都是一个
五、缓存击穿 && 缓存雪崩这之后过了一段时间太平日子,直到那一天··· 有一次,MySQL那家伙正优哉游哉的摸鱼,突然一大堆请求给他怼了过去,给他打了一个措手不及。 一阵忙活之后,MySQL怒气冲冲的找到了我,“兄弟,咋回事啊,怎么一下子来的这么猛”
我查看了日志,赶紧解释到:“大哥,实在不好意思,刚刚有一个热点数据到了过期时间,被我删掉了,不巧的是随后就有对这个数据的大量查询请求来了,我这里已经删了,所以请求都发到你那里来了” “你这干的叫啥事,下次注意点啊”,MySQL大哥一脸不高兴的离开了。 这一件小事我也没怎么放在心上,随后就抛之脑后了,却没曾想几天之后竟捅了更大的篓子。 那一天,又出现了大量的网络请求发到了MySQL那边,比上一次的规模大得多,MySQL大哥一会儿功夫就给干趴下了好几次! 等了好半天这一波流量才算过去,MySQL才缓过神来。 “老弟,这一次又是什么原因?”,MySQL大哥累的没了力气。 “这一次比上一次更不巧,这一次是一大批数据几乎同时过了有效期,然后又发生了很多对这些数据的请求,所以比起上一次这规模更大了”
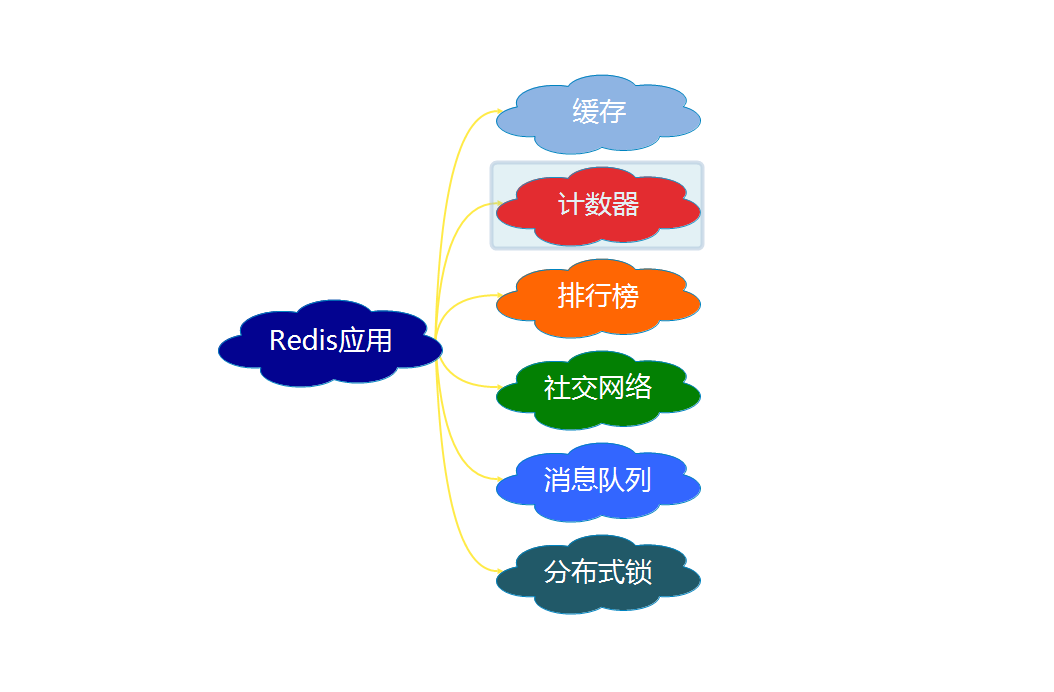
MySQL大哥听了眉头一皱,“那你倒是想个办法啊,三天两头折磨我,这谁顶得住啊?” “其实我也很无奈,这个时间也不是我设置的,要不我去找应用程序说说,让他把缓存过期时间设置的均匀一些?至少别让大量数据集体失效” “走,咱俩一起去” 后来,我俩去找应用程序商量了,不仅把键值的过期时间随机了一下,还设置了热点数据永不过期,这个问题缓解了不少。哦对了,我们还把这两次发生的问题分别取了个名字:缓存击穿和缓存雪崩。 我们终于又过上了舒适的日子··· 六、我可以用来干什么
作者: RDIF 出处: http://www.cnblogs.com/huyong/ 该文章在 2024/7/16 16:35:47 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886